🏎💨 Accelerating NeRFs: Optimizing Neural Radiance Fields with Specialized Hardware Architectures
William Shen*, Willie McClinton*
MIT CSAIL
Abstract
Neural Radiance Fields (NeRFs) have recently gained widespread interest not only from computer vision and graphics researchers, but also from cinematographers, visual effects artists, and roboticists. However, their high computational requirements remain a key bottleneck which limit their widespread use. Despite substantial software and algorithmic improvements, limited attention has been paid to the hardware acceleration potential of NeRFs.
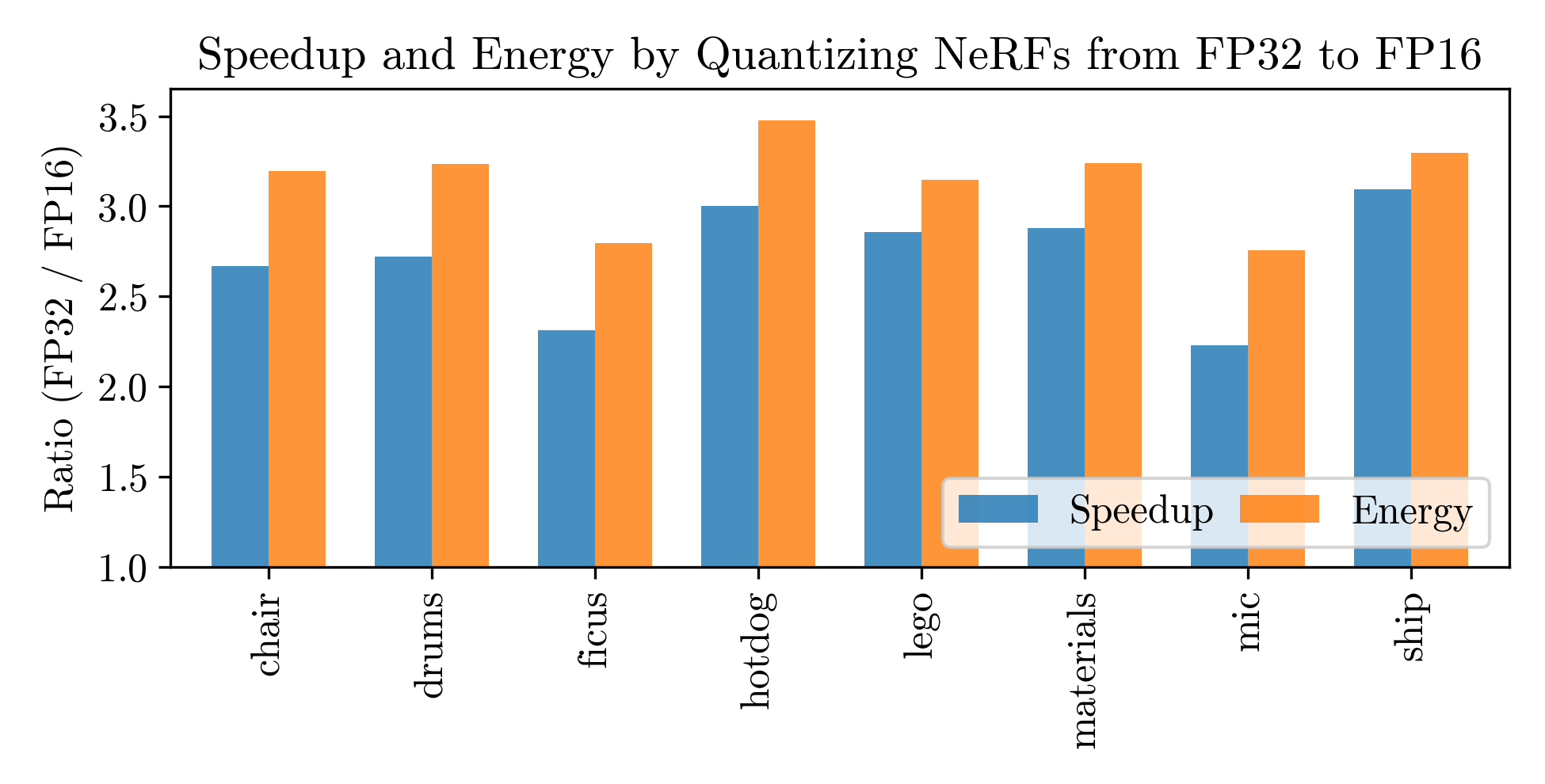
We aim to explore this untapped potential and conduct an in-depth profile of MLP-based NeRFs. We identify that the input activations of the fully-connected (FC) layers have an average sparsity of 65.8% due to the use of ReLUs, and the weights of ray samples for volumetric rendering have an average sparsity of 33.8%. We exploit these sparsities using an Eyeriss-based architecture with sparse optimizations, resulting in over 50% improvements in performance and energy for the MLP. Finally, we study post-training FP16 quantization on a GPU, resulting in 2.7x and 3.1x improvements in rendering speed and energy consumption, respectively.
Our proposed methods demonstrate the potential for hardware acceleration to significantly speed up NeRFs, making them more accessible for a wider range of applications and low-compute devices.
NeRF Videos
Videos rendered from our NeRF implementation using 32-bit floating point precision.
Turn your phone sideways to view.
Exploiting Activation Sparsity
Our NeRF model consists of 12 fully-connected (FC) layers, 10 of which use the ReLU activation function hence resulting in sparse activations. This results in a significant number of ineffectual computations, which spend unnecessary energy and computation time.
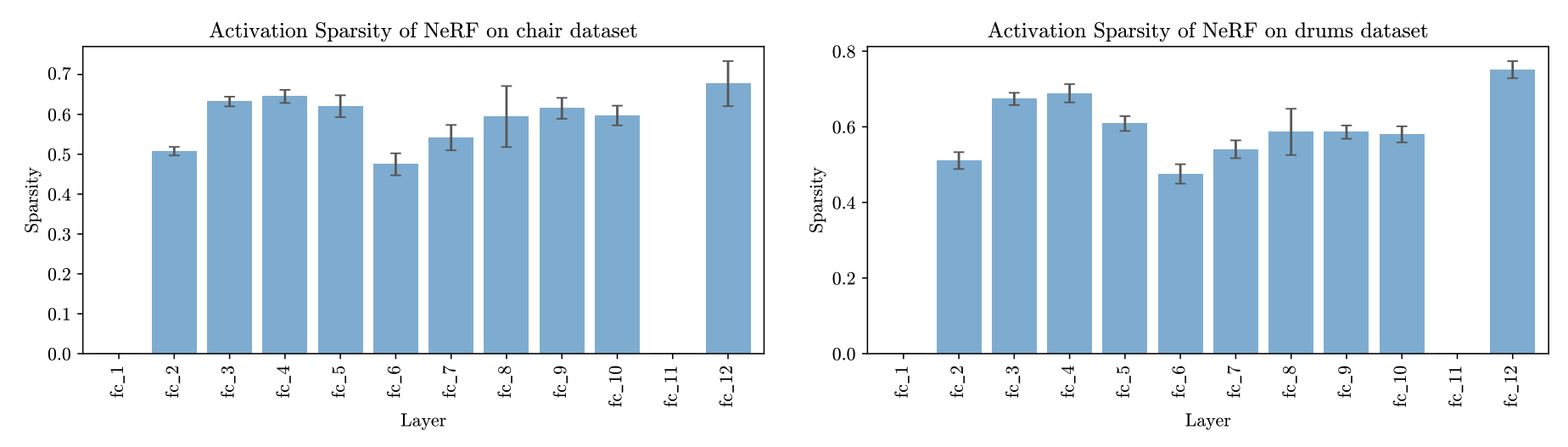
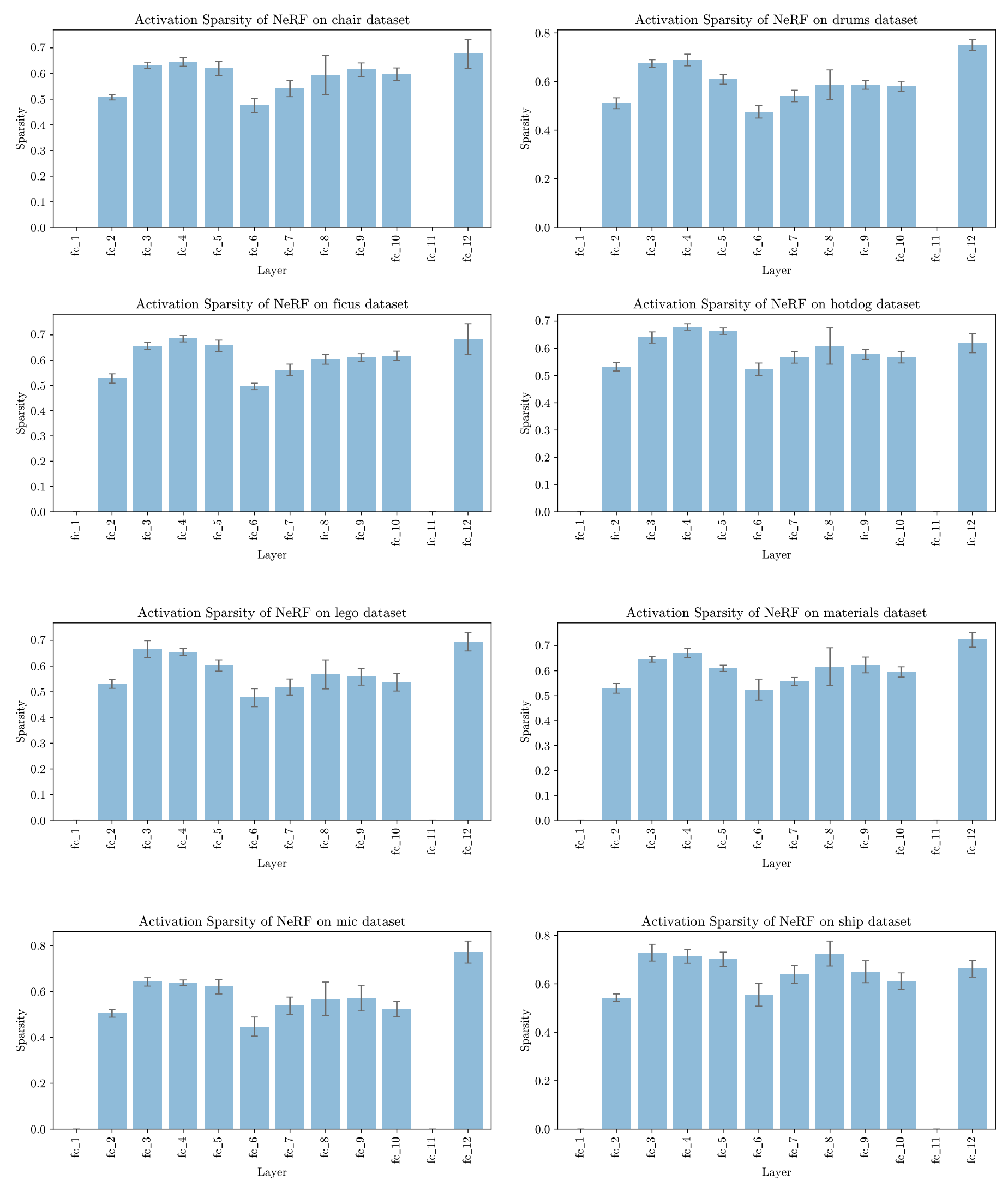
We propose to exploit this activation sparsity by using compressed representations, along with gating and skipping to avoid carrying out unnecesary computations. We profile the sparsity of the activations of the FC layers of NeRFs trained on the synthetic dataset benchmark, and show the input activation sparsities in the figures below.
We find that the overall input activation sparsity is 65.8% across the FC layers, excluding fc_1 and fc_11. Note that fc_1 receives the position-encoded ray samples while fc_11 receives the output from fc_10 which does not have an activation function.
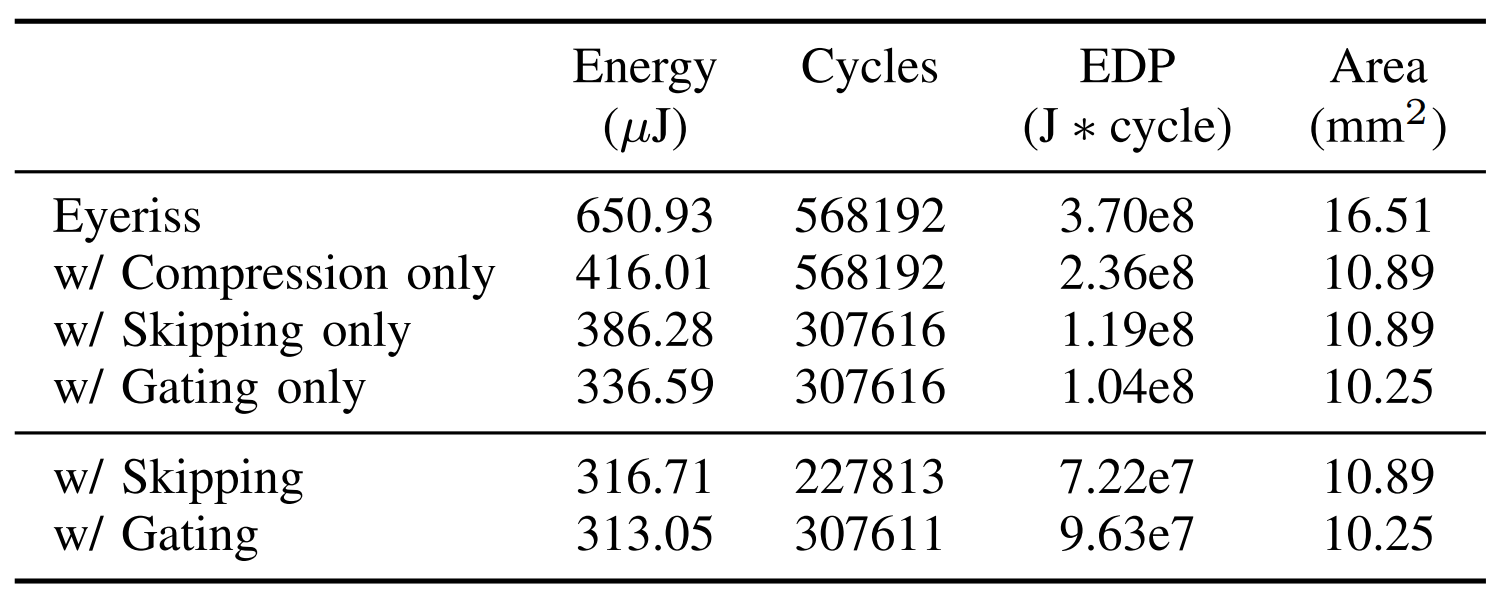
We use the Eyeriss architecture to accelerate the NeRF model, and gain a significant reduction in energy and cycles by exploiting the activation sparsity. See the table below for the results and the paper for more details.
Accelerating Volumetric Rendering
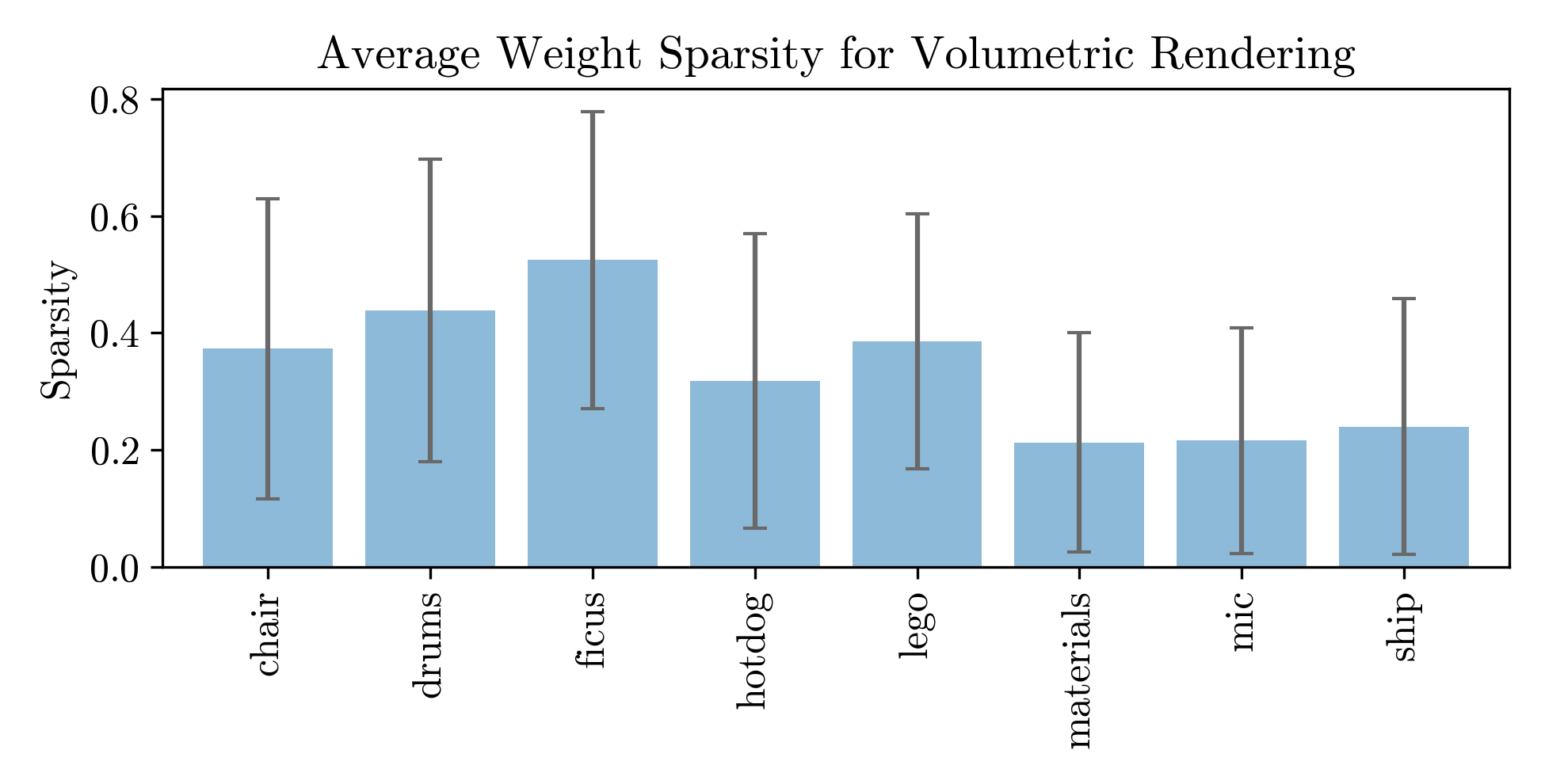
We find that the density-based weights used by volumetric rendering also exhibit an average 33.8% sparsity. We similarly exploit this with an Eyeriss-based architecture. See the paper for more details.
Quantization
The NeRF models by default use 32-bit floating point numbers (FP32). We quantize the models to FP16 and achieve significant speedups and reductions in energy (>2.5-3x 🏎💨 speed up in rendering time) at the cost of marginally decreased peak signal-to-noise ratio (PSNR).
While the PSNR is decreased, it is difficult to observe any visible difference between the images rendered from the FP32 and FP16 models. Thus, FP16 could be sufficient for many applications and additionally comes at the benefit of 2x smaller model size (from 2.4MB to 1.2MB).
Note: we run FP32 and FP16 using PyTorch on a NVIDIA RTX 3090 GPU to determine the render time. We estimate energy by multiplying the render time by the average power consumption of the GPU.
Lego (FP32)
PSNR (avg) = 33.72 dB
🐌 Render Time = 154.57s
🏭 Energy = 49.98 kJ
Lego (FP16)
PSNR (avg) = 32.74 dB
🏎💨 Render Time = 54.09s
🔋 Energy = 15.89 kJ


Videos not showing? Try refresh